Omnilingual ASR是Meta AI研发的自动语音识别系统,可支持一千六百多种语言,其中包含五百种低资源语言。该系统对wav2vec 2.0编码器进行扩展,使其参数达到70亿,并引入两种解码器,以此实现出色性能,有78%的语言字符错误率低于10%。Omnilingual ASR框架采用社区驱动模式,用户仅需提供少量样本就能将其扩展至新的语言。此外,Meta还开源了Omnilingual ASR Corpus数据集以及Omnilingual wav2vec 2.0这一全新的自监督式大规模多语言语音表示模型,为全球语音技术的发展提供助力,进而推动语言平等与文化交流。

Omnilingual ASR的核心功能多语言语音转写:该系统可实现超1600种语言的语音到文本转换,涵盖众多低资源语言及此前未被AI覆盖的语言类型。社区拓展特性:用户仅需提供少量音频与文本样本,即可将模型适配至新语言,无需依赖海量训练数据或专业技术背景。优异性能表现:在78%的目标语言中,字符错误率(CER)控制在10%以下,处于行业领先地位。灵活模型选型:提供从300M轻量版本到7B大参数版本的多类模型,满足不同设备部署及场景需求。开源协作支持:开放Omnilingual wav2vec 2.0模型与Omnilingual ASR Corpus数据集,助力全球开发者与研究者开展深度研发。Omnilingual ASR的技术机制wav2vec 2.0升级:将wav2vec 2.0编码器扩展至70亿参数规模,可从原始语音数据中提取更丰富的多语言语义特征。双解码器结构:采用传统连接主义时间分类(CTC)解码器与Transformer-based解码器结合的架构,后者融合大型语言模型(LLM)技术,有效提升长尾语言的识别性能。上下文适配能力:受LLM启发,模型可通过少量上下文示例快速适配新语言,无需大规模训练或复杂参数调整。多语言数据支撑:训练语料整合公开数据集与社区贡献的语音记录,覆盖大量低资源语言,为模型构建全面的语言基础。Omnilingual ASR的资源链接官方网站:https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/代码仓库:https://github.com/facebookresearch/omnilingual-asr模型平台:https://huggingface.co/datasets/facebook/omnilingual-asr-corpus学术论文:https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/Omnilingual ASR的应用领域跨语言沟通:辅助不同语言使用者实现实时语音交互,消除语言隔阂,推动国际合作与文化交流。低资源语言保护:为濒危或低资源语言提供高质量语音转写工具,支持语言的保存与传承工作。教育教学场景:在多语言教育中辅助教学活动,帮助学生练习发音,或为语言学习者提供即时语音转写服务。智能助手扩展:为语音助手增加更多语言支持,使其服务范围覆盖更广泛的用户群体。内容生产领域:自动转写多语言音视频内容,提升创作效率,支持多语言字幕生成等应用。

《桃源记2》中石作的建造方式
发布时间:2025-11-26
《英雄联盟手游》5.3d版本更新内容全知晓
发布时间:2025-11-27
《央视影音》把视频保存至手机相册的方法汇总
发布时间:2025-11-27
《原神》中罗莎莉亚圣遗物词条的搭配攻略
发布时间:2025-11-28
《英雄冒险团》战士属性加点攻略分享
发布时间:2025-11-28
《画世界》中向下合并图层的操作方法
发布时间:2025-11-29
第五人格毛利小五郎皮肤好不好?来看第五人格毛利小五郎皮肤介绍
发布时间:2025-11-29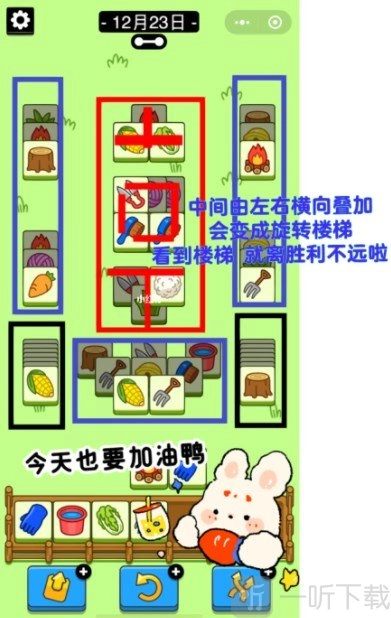
《羊了个羊12月23日通关攻略,12.23过关技巧大揭秘》
发布时间:2025-11-30